Hallucinated citations are a hot topic in 2026. Just this month, large-scale analyses published in The Lancet and arXiv highlighted the scale and scope of the problem. And last week arXiv announced a severe penalty for submitting a manuscript with hallucinations.
At Paperpile, it’s our job to be obsessed about citation accuracy. So we built a new tool to screen your BibTeX for errors before submitting a preprint: the Paperpile Citation Checker. Alongside the tool we’ll also share some practical tips for authors, drawing from recent literature on hallucinations and a novel simulation experiment from our team.
Introducing the Paperpile Citation Checker
Today we are releasing the Paperpile Citation Checker, a free web tool that checks every reference in a BibTeX file for correctness.
Paste in your references and the Citation Checker verifies each entry in real time. When it's done, you can download an updated BibTeX file or share the URL with your coauthors.
This new tool is quicker and easier to use than existing alternatives, and we’ll continue to improve it based on feedback from the community. Email support@paperpile.com with suggestions or thoughts.
How hallucinations happen
If you thought hallucinations were an artifact of previous-generation models or outdated ways of using AI, this graph from Zhao et al. 2026 might change your mind:
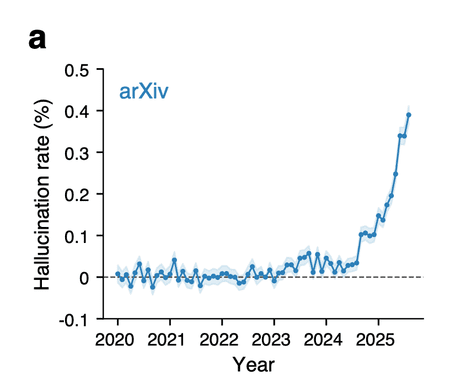
They estimate that ~0.4% of all citations in recent arXiv submissions are hallucinated! And these artifacts are becoming more, not less, common over time, despite ongoing AI model improvements intended to reduce hallucinations.
Which begs the question: why is this still happening?
We found an important clue in a series of comments in the OpenReview system, titled Analysis and Fixes of Hallucinated Citations in Park and Cho 2025. The comment thread is attached to a NeurIPS submission that contained hallucinated citations. In an unusually frank postmortem, the lead author explains exactly how things went wrong:
We (Park & Cho) used a large-scale language model (LLM; specifically ChatGPT) to generate the citations after giving it author-year in-text citations, titles, or their paraphrases.
The authors also published an updated version of their manuscript with a fixed bibliography. Here’s a look at both versions in our Citation Checker, showing how much cleanup was required (the original version is on the left; potential hallucinations are flagged in red):
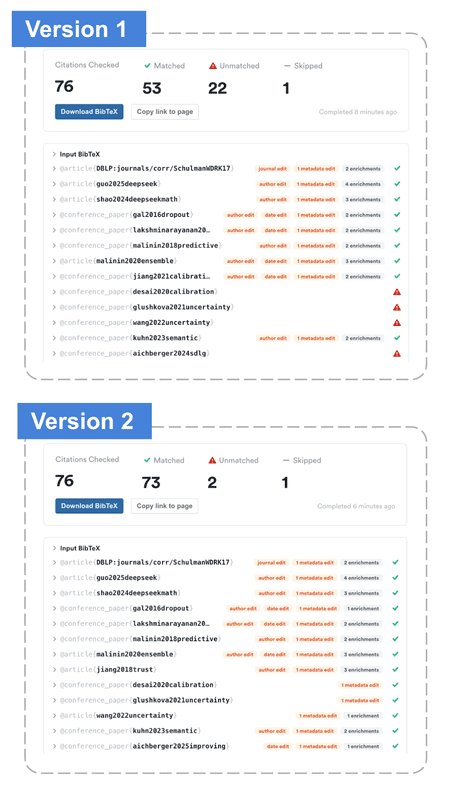
While the Park and Cho case study is just one anecdote, it carries two important insights:
- Asking an AI assistant to auto-complete bibliographic details for a series of citations is an emerging use case for AI in research. Authors appreciate not manually chasing down BibTeX from each cited source.
- When used poorly, an AI assistant can turn real paraphrased citations into fake ones by hallucinating metadata rather than looking it up.
Simulating nonsense
Using Park and Cho’s corrected bibliography as a starting point, we ran a small simulation study to further understand the dynamics of hallucinated citations. The process was as follows:
- Generate a paraphrased citation for each of the 76 input references (e.g. “Shulman et al. 2017 Proximal”).
- Randomly sample 20 citations at a time.
- Send the batch to an LLM with a simple prompt asking to convert the paraphrased citations into properly-formatted BibTeX.
- Evaluate the LLM-generated BibTeX for hallucinations.
We sought to answer the following questions:
- How much does model size (the number of parameters inside an AI model) impact hallucination rate?
- Do models hallucinate less when given access to tools like web search?
- What factors make some references more likely to trigger a hallucination than others?
First, we looked at the overall hallucination rate by model and tool use:
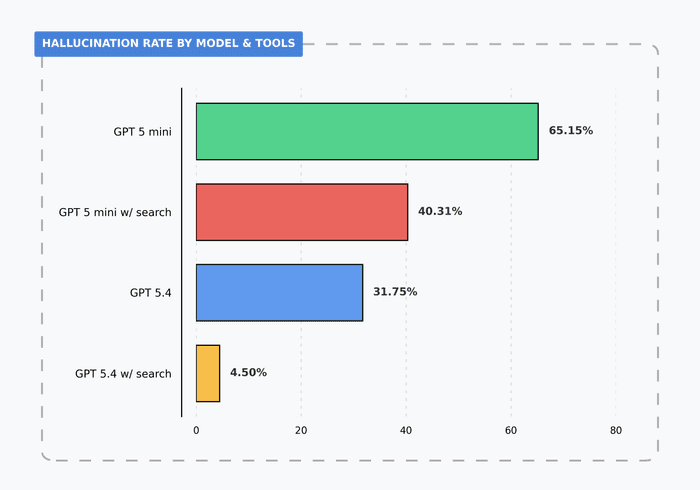
We see that model size has a large impact on performance. Adding the web search tool leads to a modest improvement for GPT-5 mini and a large improvement for GPT-5.4.
We then focused on the GPT 5.4 runs (without search) and asked whether the citation count of the paraphrased reference impacts the hallucination rate:
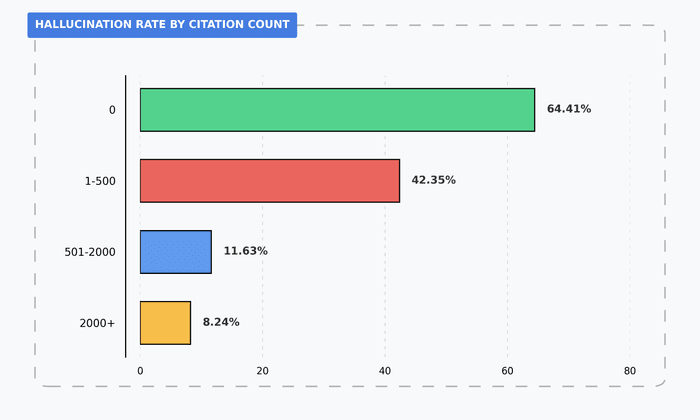
This strong correlation is quite intuitive: a highly-cited paper has many chances to be included repeatedly in a model’s training data, making it more “in-distribution” than a paper with very few citations.
These results give us some practical takeaways:
- Larger models are better.
- This means the “thinking” or “pro” model in an AI assistant will outperform the “instant” or “lite” model.
- Incorporating web search results can dramatically reduce hallucinations.
- Newer and less-cited references are more prone to AI-induced hallucinations.
Are today’s tools hallucination-proof?
Finally, we ran some manual tests using today’s most popular AI assistants and the same paraphrased citation inputs. (For each product, we chose the latest and largest model available and the standard / medium thinking level.)
We evaluated the Bibtex output from each model against the Citation Checker:
ChatGPT and Claude were both relatively clean (the one unmatched reference from ChatGPT is a false positive), but Gemini had 3 legitimate hallucinations.
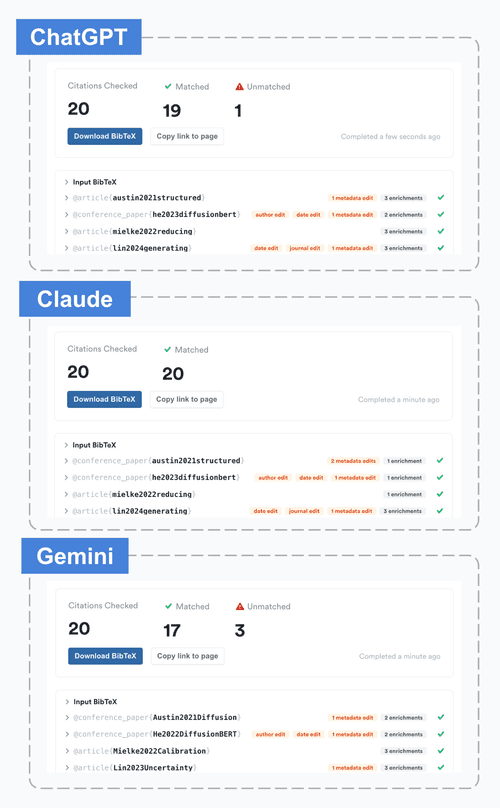
This was a quick spot-check, not a formal evaluation, but results were qualitatively similar across a few independent runs in each tool.
What makes ChatGPT and Claude perform better? As best we can tell, they are much more aggressive in their agentic tool-calling behavior. You can verify this by viewing their detailed thinking and tool calling process: both assistants ran dozens of web searches while generating a response.
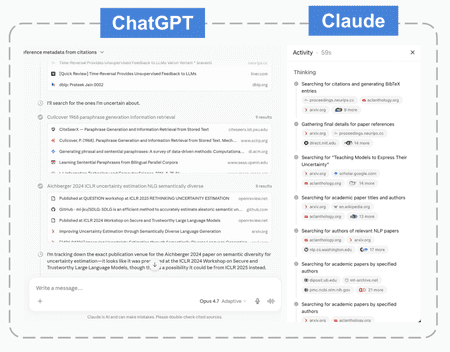
The pattern is clear: web search is what grounds a modern AI assistant when working with literature metadata.
Practical tips for authors
Our overall recommendation for authors: using AI to generate a bibliography is not worth the risk. The latest generation of AI assistants are capable of generating well-grounded BibTeX from spotty or paraphrased inputs, but they are still not 100% reliable.
With increasing awareness of the problem, we expect journals and preprint servers to quickly adopt automated verification tools to screen submissions for citation accuracy.
Here are two easy ways to stay on top of your bibliography:
- For a simple sanity-check, use the Citation Checker tool.
- If you want more power & flexibility, use a modern reference manager like Paperpile.